“子查询及连接”的版本间差异
跳到导航
跳到搜索
(建立内容为“category:MySQL”的新页面) |
无编辑摘要 |
||
| 第1行: | 第1行: | ||
[[category:MySQL]] | [[category:MySQL]] | ||
== 关于 == | |||
在开发中,数据查询语句使用较多的就是子查询与连接查询: | |||
# 子查询:将内部查询语句的结果作为依据,得到外部查询的结果集。【会生成临时表】 | |||
# 连接查询:将两个(多个)表通过主外键关联,并以某个表为基准产生一个记录集。 | |||
# union:将多个记录集并在一起,成为一个新的记录集。 | |||
== 子查询 == | |||
=== 子查询的类型 === | |||
MySQL 中子查询的分类: | |||
* 可以从 EXPLAIN 查询类型(“select_type”)中看到。 | |||
# “SIMPLE”:简单的“SELECT”(不使用“UNION”或 子查询); | |||
# “PRIMARY”:最外层的“SELECT”; | |||
# “'''SUBQUERY'''”:子查询中的第一个“SELECT”; | |||
# “UNION”:“UNION”中的第二个或之后的“SELECT”语句; | |||
# “'''DEPENDENT SUBQUERY'''”:子查询中的第一个“SELECT”,依赖于外部查询,称为“'''依赖子查询'''”或“'''相关子查询'''”;【严重消耗性能】 | |||
# “DEPENDENT UNION”:“UNION”中的第二个或之后的“SELECT”语句,依赖于外部查询; | |||
# “'''DERIVED'''”:'''派生表''',即:被驱动的“SELECT”子查询('''位于FROM子句的子查询'''); | |||
# “'''MATERIALIZED'''”:'''被实体化的子查询'''; | |||
# “UNION RESULT”:“UNION”的结果; | |||
# “UNCACHEABLE SUBQUERY”:'''不可缓存子查询''':其结果无法缓存,必须针对外部查询的每一行重新进行评估;【不可被物化,每次都需要计算】 | |||
# “UNCACHEABLE UNION”:不可缓存子查询的“UNION”中的第二个或之后的“SELECT”; | |||
按照子查询的位置,可分为: | |||
# from clause:(from子句中)即“DERIVED”;【会被 materialize(实体化)】 | |||
# where clause:(where子句中)即“SUBQUERY”、“DEPENDENT SUBQUERY”;【不会被 materialize(实体化)】 | |||
按照子查询与外部查询的关系,可分为: | |||
# 相关子查询:子查询依赖于外部查询的返回值;【一般只出现在“exists”或“not exists”的子查询中】 | |||
# 非相关子查询:子查询不依赖外部查询的返回值。 | |||
=== MySQL对“子查询”的自动优化 === | |||
MySQL 可以通过以下方式来优化子查询:【“半联接”、“实体化”、“EXISTS策略”、“合并”】 | |||
# 对于“IN”(或“=ANY”)子查询,优化器具有以下选择: | |||
#* 半连接 | |||
#* 实体化 | |||
#* EXISTS策略 | |||
# 对于“NOT IN”(或“<>ALL”)子查询,优化器具有以下选择: | |||
#* 实体化 | |||
#* EXISTS 策略 | |||
# 对于“派生表”,优化器具有以下选择(这也适用于视图引用): | |||
#* 将派生表合并到外部查询块中 | |||
#* 将派生表实体化为内部临时表 | |||
见:“[[MySQL 优化:优化 SQL 语句:优化子查询,派生表和视图引用]]” | |||
=== “in”子查询 === | |||
=== “exists”子查询 === | |||
== 连接 == | |||
=== 连接的类型 === | |||
连接查询主要分为三种:、、。 | |||
# '''内连接'''(INNER JOIN): | |||
#: 返回连接表中符合连接条件和查询条件的数据行。 | |||
#: [[File:连接查询:内连接(inner join).png|400px]] | |||
#: <syntaxhighlight lang="mysql" highlight=""> | |||
SELECT a.*, b.* FROM employees a INNER JOIN departments b ON a.department_id=b.department_id | |||
</syntaxhighlight> | |||
## '''等值连接''': | |||
##: 在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。 | |||
##*【和常说的内连接是一回事情】 | |||
##: <syntaxhighlight lang="mysql" highlight=""> | |||
select * from book as a,stu as b where a.sutid = b.stuid -- 隐式内连接 | |||
select * from book as a inner join stu as b on a.sutid = b.stuid -- 显式内连接(inner可省略) | |||
</syntaxhighlight> | |||
## '''不等值连接''': | |||
##: 在连接条件使用除等于运算符以外的其它比较运算符(>、>=、<=、<、!>、!<和<>)比较被连接的列的列值。 | |||
##*【并不常用】 | |||
## '''自然连接'''(NATURAL JOIN): | |||
##: 在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。 | |||
##* 自然连接不仅要求连接的两个字段必须同名,还要求将结果中重复的属性列去掉。 | |||
##: <syntaxhighlight lang="mysql" highlight=""> | |||
SELECT * FROM student NATURAL JOIN score | |||
</syntaxhighlight> | |||
# '''外连接'''(OUTER JOIN): | |||
## '''左外联接'''(LEFT JOIN、LEFT OUTER JOIN): | |||
##: 以左表为基准进行连接。将左表没有的对应项显示,右表的列为 NULL。 | |||
##: [[File:连接查询:左外连接(left outer join).png|400px]] | |||
##: <syntaxhighlight lang="mysql" highlight=""> | |||
SELECT a.* FROM employees a LEFT JOIN departments b ON b.department_id=a.department_id | |||
</syntaxhighlight> | |||
## '''右外链接'''(RIGHT JOIN、RIGHT OUTER JOIN): | |||
##: 以右表为基准进行连接。将右表没有的对应项显示,左表的列为 NULL。 | |||
##: [[File:连接查询:右外连接(right outer join).png|400px]] | |||
##: <syntaxhighlight lang="mysql" highlight=""> | |||
SELECT a.* FROM employees a RIGHT JOIN departments b ON b.department_id=a.department_id | |||
</syntaxhighlight> | |||
## '''全外连接(全连接)'''(FULL JOIN、FULL OUTER JOIN): | |||
##: 完整外部联接返回左表和右表中的所有行。 | |||
##: 当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。 | |||
##: [[File:连接查询:全外连接(full outer join).png|400px]] | |||
##: <syntaxhighlight lang="mysql" highlight=""> | |||
//oracle写法 | |||
SELECT table1.column1, table2.column2... | |||
FROM table1 | |||
FULL JOIN table2 | |||
ON table1.common_field = table2.common_field; | |||
</syntaxhighlight> | |||
##* oracle 里面有“full join”,但是在 mysql 中没有“full join”。我们可以使用“'''union'''”来达到目的: | |||
##*: <syntaxhighlight lang="mysql" highlight=""> | |||
//mysql写法 | |||
SELECT a.* FROM employees a LEFT JOIN departments b ON a.department_id = b.department_id | |||
UNION | |||
SELECT a.* FROM employees a RIGHT JOIN departments b ON a.department_id = b.department_id | |||
</syntaxhighlight> | |||
# '''交叉连接'''(cross join): | |||
#: 交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作'''笛卡尔积'''。 | |||
#: <syntaxhighlight lang="mysql" highlight=""> | |||
select * from book as a cross join stu as b order by a.id | |||
</syntaxhighlight> | |||
#: | |||
=== “嵌套循环关联”算法 === | |||
见:“[[MySQL 优化:优化 SQL 语句:优化 SELECT 语句]]”中“嵌套循环连接算法”一节 | |||
== 连接查询和子查询的效率 == | |||
2021年5月7日 (五) 17:17的版本
关于
在开发中,数据查询语句使用较多的就是子查询与连接查询:
- 子查询:将内部查询语句的结果作为依据,得到外部查询的结果集。【会生成临时表】
- 连接查询:将两个(多个)表通过主外键关联,并以某个表为基准产生一个记录集。
- union:将多个记录集并在一起,成为一个新的记录集。
子查询
子查询的类型
MySQL 中子查询的分类:
- 可以从 EXPLAIN 查询类型(“select_type”)中看到。
- “SIMPLE”:简单的“SELECT”(不使用“UNION”或 子查询);
- “PRIMARY”:最外层的“SELECT”;
- “SUBQUERY”:子查询中的第一个“SELECT”;
- “UNION”:“UNION”中的第二个或之后的“SELECT”语句;
- “DEPENDENT SUBQUERY”:子查询中的第一个“SELECT”,依赖于外部查询,称为“依赖子查询”或“相关子查询”;【严重消耗性能】
- “DEPENDENT UNION”:“UNION”中的第二个或之后的“SELECT”语句,依赖于外部查询;
- “DERIVED”:派生表,即:被驱动的“SELECT”子查询(位于FROM子句的子查询);
- “MATERIALIZED”:被实体化的子查询;
- “UNION RESULT”:“UNION”的结果;
- “UNCACHEABLE SUBQUERY”:不可缓存子查询:其结果无法缓存,必须针对外部查询的每一行重新进行评估;【不可被物化,每次都需要计算】
- “UNCACHEABLE UNION”:不可缓存子查询的“UNION”中的第二个或之后的“SELECT”;
按照子查询的位置,可分为:
- from clause:(from子句中)即“DERIVED”;【会被 materialize(实体化)】
- where clause:(where子句中)即“SUBQUERY”、“DEPENDENT SUBQUERY”;【不会被 materialize(实体化)】
按照子查询与外部查询的关系,可分为:
- 相关子查询:子查询依赖于外部查询的返回值;【一般只出现在“exists”或“not exists”的子查询中】
- 非相关子查询:子查询不依赖外部查询的返回值。
MySQL对“子查询”的自动优化
MySQL 可以通过以下方式来优化子查询:【“半联接”、“实体化”、“EXISTS策略”、“合并”】
- 对于“IN”(或“=ANY”)子查询,优化器具有以下选择:
- 半连接
- 实体化
- EXISTS策略
- 对于“NOT IN”(或“<>ALL”)子查询,优化器具有以下选择:
- 实体化
- EXISTS 策略
- 对于“派生表”,优化器具有以下选择(这也适用于视图引用):
- 将派生表合并到外部查询块中
- 将派生表实体化为内部临时表
见:“MySQL 优化:优化 SQL 语句:优化子查询,派生表和视图引用”
“in”子查询
“exists”子查询
连接
连接的类型
连接查询主要分为三种:、、。
- 内连接(INNER JOIN):
- 返回连接表中符合连接条件和查询条件的数据行。

SELECT a.*, b.* FROM employees a INNER JOIN departments b ON a.department_id=b.department_id
- 等值连接:
- 在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
- 【和常说的内连接是一回事情】
select * from book as a,stu as b where a.sutid = b.stuid -- 隐式内连接 select * from book as a inner join stu as b on a.sutid = b.stuid -- 显式内连接(inner可省略)
- 不等值连接:
- 在连接条件使用除等于运算符以外的其它比较运算符(>、>=、<=、<、!>、!<和<>)比较被连接的列的列值。
- 【并不常用】
- 自然连接(NATURAL JOIN):
- 在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。
- 自然连接不仅要求连接的两个字段必须同名,还要求将结果中重复的属性列去掉。
SELECT * FROM student NATURAL JOIN score
- 外连接(OUTER JOIN):
- 左外联接(LEFT JOIN、LEFT OUTER JOIN):
- 以左表为基准进行连接。将左表没有的对应项显示,右表的列为 NULL。
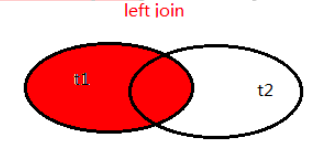
SELECT a.* FROM employees a LEFT JOIN departments b ON b.department_id=a.department_id
- 右外链接(RIGHT JOIN、RIGHT OUTER JOIN):
- 以右表为基准进行连接。将右表没有的对应项显示,左表的列为 NULL。
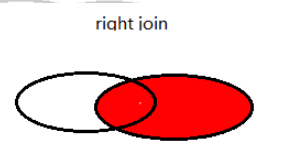
SELECT a.* FROM employees a RIGHT JOIN departments b ON b.department_id=a.department_id
- 全外连接(全连接)(FULL JOIN、FULL OUTER JOIN):
- 完整外部联接返回左表和右表中的所有行。
- 当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
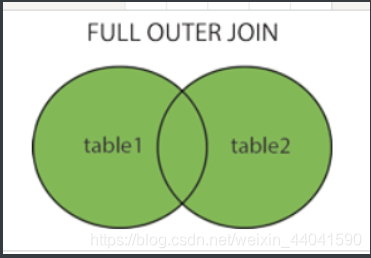
//oracle写法 SELECT table1.column1, table2.column2... FROM table1 FULL JOIN table2 ON table1.common_field = table2.common_field;
- oracle 里面有“full join”,但是在 mysql 中没有“full join”。我们可以使用“union”来达到目的:
//mysql写法 SELECT a.* FROM employees a LEFT JOIN departments b ON a.department_id = b.department_id UNION SELECT a.* FROM employees a RIGHT JOIN departments b ON a.department_id = b.department_id
- 左外联接(LEFT JOIN、LEFT OUTER JOIN):
- 交叉连接(cross join):
- 交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
select * from book as a cross join stu as b order by a.id




“嵌套循环关联”算法
见:“MySQL 优化:优化 SQL 语句:优化 SELECT 语句”中“嵌套循环连接算法”一节