子查询及连接
关于
在开发中,数据查询语句使用较多的就是子查询与连接查询:
- 子查询:将内部查询语句的结果作为依据,得到外部查询的结果集。【会生成临时表】
- 连接查询:将两个(多个)表通过主外键关联,并以某个表为基准产生一个记录集。
- union:将多个记录集并在一起,成为一个新的记录集。
子查询
子查询的类型
MySQL 中子查询的分类:
- 可以从 EXPLAIN 查询类型(“select_type”)中看到。
- “SIMPLE”:简单的“SELECT”(不使用“UNION”或 子查询);
- “PRIMARY”:最外层的“SELECT”;
- “SUBQUERY”:子查询中的第一个“SELECT”;
- “UNION”:“UNION”中的第二个或之后的“SELECT”语句;
- “DEPENDENT SUBQUERY”:子查询中的第一个“SELECT”,依赖于外部查询,称为“依赖子查询”或“相关子查询”;【严重消耗性能】
- “DEPENDENT UNION”:“UNION”中的第二个或之后的“SELECT”语句,依赖于外部查询;
- “DERIVED”:派生表,即:被驱动的“SELECT”子查询(位于FROM子句的子查询);
- “MATERIALIZED”:被实体化的子查询;
- “UNION RESULT”:“UNION”的结果;
- “UNCACHEABLE SUBQUERY”:不可缓存子查询:其结果无法缓存,必须针对外部查询的每一行重新进行评估;【不可被物化,每次都需要计算】
- “UNCACHEABLE UNION”:不可缓存子查询的“UNION”中的第二个或之后的“SELECT”;
按照子查询的位置,可分为:
- from clause:(from子句中)即“DERIVED”;【会被 materialize(实体化)】
- where clause:(where子句中)即“SUBQUERY”、“DEPENDENT SUBQUERY”;【不会被 materialize(实体化)】
按照子查询与外部查询的关系,可分为:
- 相关子查询:子查询依赖于外部查询的返回值;【一般只出现在“exists”或“not exists”的子查询中】
- 非相关子查询:子查询不依赖外部查询的返回值。
MySQL对“子查询”的自动优化
MySQL 可以通过以下方式来优化子查询:【“半联接”、“实体化”、“EXISTS策略”、“合并”】
- 对于“IN”(或“=ANY”)子查询,优化器具有以下选择:
- 半连接
- 实体化
- EXISTS策略
- 对于“NOT IN”(或“<>ALL”)子查询,优化器具有以下选择:
- 实体化
- EXISTS 策略
- 对于“派生表”,优化器具有以下选择(这也适用于视图引用):
- 将派生表合并到外部查询块中
- 将派生表实体化为内部临时表
“in”与“exists”
“in”子查询:
- in( 常量列表 ):
- 相当于多个or条件的叠加。
select * from user where userId in (1, 2, 3); -- 等效于 select * from user where userId = 1 or userId = 2 or userId = 3;
- in( select子查询 ):
- 这种情况一般是作为 where 语句后面的一个条件。
- MySQL 5.6.5 之后可以将 where 之后的 select 物化(实体化)的情况。在这种情况下mysql会在内存中创建一个临时表,然后使用in(常量列表)的形式进行查询。
- 注意:“in”不是进行的索引范围扫描,而是进行单独的等值查询。
“exists”子查询:对外表进行循环查询,再根据exists条件语句过滤符合的数据。
“in”与“exists”的效率:
- MySQL 会对“in”子查询进行优化,其中之一就是使用“EXISTS策略”。
MySQL 中二者区别在于:
- “in”语句是把外表和内表作 hash 连接(本质是基于内表查询结果集作loop循环);
- 【所以内表是否使用索引对“in( select子查询 )”查询影响更大】
- 而“exists”语句是对外表作loop循环,每次loop循环再对内表进行查询。
- 【所以外查询是否使用索引对“exists”影响更大】
所以,一直认为的“exists”比“in”语句的效率要高,并不准确的。而是要区分环境的:
- 如果查询的两个表大小相当,那么用“in”与“exists”差别不大。
- 如果两个表大小悬殊,则子查询表大的用“exists”,子查询表小的用“in”。【可能受不同版本的优化的影响而不一】
- 而对于“not in”(反向范围不使用索引)与“not exists”,由其执行过程可知“not exists”效率更高。
连接
连接的类型
连接查询类型:
- 内连接(INNER JOIN):
- 返回连接表中符合连接条件和查询条件的数据行。
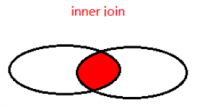
-- 隐式内连接(用 where 关联字段) SELECT a.*, b.* FROM employees a, departments b where a.sutid = b.stuid -- 显式内连接(inner可省略,用 on 关联字段,字段名一致可用 using 关联字段) SELECT a.*, b.* FROM employees a INNER JOIN departments b ON a.department_id=b.department_id SELECT a.*, b.* FROM employees a INNER JOIN departments b using(department_id)
SELECT a.*, b.* FROM employees a INNER JOIN departments b ON a.department_id=b.department_id
- 等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
- 【和常说的内连接是一回事情】
- 不等值连接:在连接条件使用除等于运算符以外的其它比较运算符(>、>=、<=、<、!>、!<和<>)比较被连接的列的列值。
- 【并不常用】
- 自然连接(NATURAL JOIN):不能加连接条件,使用两个表共有的字段来“自然”地链接,同时会省略共有的字段,其作用相同于内连接使用“using”子句来查询。
- 自然连接不仅要求连接的两个字段必须同名,还要求将结果中重复的属性列去掉。
SELECT * FROM student NATURAL JOIN score
- 外连接(OUTER JOIN):
- 左外联接(LEFT JOIN、LEFT OUTER JOIN):
- 以左表为基准进行连接。将左表没有的对应项显示,右表的列为 NULL。
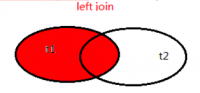
SELECT a.* FROM employees a LEFT JOIN departments b ON b.department_id=a.department_id
- 右外链接(RIGHT JOIN、RIGHT OUTER JOIN):
- 以右表为基准进行连接。将右表没有的对应项显示,左表的列为 NULL。
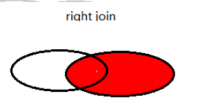
SELECT a.* FROM employees a RIGHT JOIN departments b ON b.department_id=a.department_id
- 全外连接(全连接)(FULL JOIN、FULL OUTER JOIN):
- 完整外部联接返回左表和右表中的所有行。
- 当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
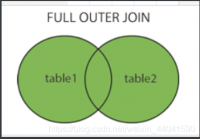
//oracle写法 SELECT table1.column1, table2.column2... FROM table1 FULL JOIN table2 ON table1.common_field = table2.common_field;
- oracle 里面有“full join”,但是在 mysql 中没有“full join”。我们可以使用“union”来达到目的:
//mysql写法 SELECT a.* FROM employees a LEFT JOIN departments b ON a.department_id = b.department_id UNION SELECT a.* FROM employees a RIGHT JOIN departments b ON a.department_id = b.department_id
- 左外联接(LEFT JOIN、LEFT OUTER JOIN):
- 交叉连接(cross join):
- 交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
select * from book as a cross join stu as b order by a.id




其他
- STRAIGHT_JOIN:拒绝Mysql语句优化的连接。
- 与内连接一样,但只能使用“on”子句,无法使用“using”子句;
select * from a straight_join b on a.id = b.id;
“嵌套循环关联”算法
- 见:“MySQL 优化:优化 SQL 语句:优化 SELECT 语句”中“嵌套循环连接算法”一节
- MySQL 中“关联(join)”一词包含的意义比一般意义上理解的要更广泛。总的来说,MySQL 认为任何一个查询都是一次“关联”,而并不仅仅是一个查询需要到两个表的匹配才叫关联,所以在MySQL中,每一个查询,每一个片段(包括子查询,设置基于表单的select)都可能是关联。
MySQL 没有实现hash连接,而是使用的“nestloop join”(嵌套循环关联):【其执行过程如同循环代码】
MySQL 先在一个表中循环取出单条数据,然后再嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。 然后根据各个表匹配的行,返回查询中需要的各个列。 MySQL 会尝试在最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行以后,MySQL 返回到上一层次关联表,看是否能够找到更多的匹配记录,依次类推迭代执行。
按照这样的方式查找第一个表记录,再嵌套查询下一个表,然后回溯到上一个表,在 MySQL 中是通过嵌套循环的方式实现,正如其名“嵌套循环关联”。
如以下关联语句:
SELECT tbl1.col1,tbl2.col2 FROM tbl1 INNER JOIN tbl2 USING (col3) WHERE tbl1.col1 in (3,4);
假设 MySQL 按照查询中的表顺序进行关联操作,则可以用下面的伪代码表示其查询过程:
outer_iter = iterator_over tbl1 where col1 in(3,4)
outer_row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3=outer_row.col3
inner_row = inner_iter.next
while inner_row
output[outer_row.col1,inner_row.col2]
inner_row = inner_iter.next
end
out_row = outer_iter.next
end
上面的执行计划对于单表查询和多表关联查询都适用,如果是一个单表查询,那么只需要完成上面的外层的基本操作。
对于外连接和上面的执行过程任然适用:
SELECT tbl1.col1 ,tbl2.col2 FROM tbl1 left outer join tbl2 using (col3) WHERE tbl1.col1 in (3,4)
可以用下面的伪代码表示其查询过程:
outer_iter = iterator over tbl1 where col1 in(3,4)
outer row = outer_iter.next
while outer_row
inner_iter = iterator over tbl2 where col3 = outer_row.col3
inner_row = inner_iter.next
if inner row
while inner_row
out_put [outer_row.col1,inner_row.col2]
inner_row = inner_iter.next
end
else
out_put[outer_row.col1,NULL]
end
outer_row = outer_iter.next
end
- 从本质上说,MySQL 对所有的类型的查询都以同样的方式运行。
- 例如,MySQL 在 from 子句中遇到的子查询时,先执行子查询,并将其结果放到一个临时表中,然后将这个临时表作为一个普通的表对待(正如其名“派生表”)。
- (MySQL 的临时表时没有任何索引的,在编写复杂的子查询和关联查询的时候需要注意这一点,这一点对 UION 查询也一样)
- 不过,不是所有的查询都可以转换成上面的形式。
- 例如,全外连接就无法通过嵌套循环和回溯的方式完成,这时当发现关联表中没有找到任何匹配行的时候,则可能是因为关联恰好是从一个没有任何匹配的表开始。这大概也是MySQL并不支持全外连接的原因。
- 还有些场景,虽然可以转换成嵌套循环的方式,但是效率却非常差。
从上面的情况我们可以看到,由于 MySQL 使用“nestloop join”(嵌套循环关联)来进行表之间的关联,所以不管是“in”子查询,“exists”子查询还是“join”连接查询,底层的实现原理都是一样的,本质上是没有任何区别的,关键的点在关联表的顺序:如果是“join”连接查询,MySQL 会自动调整表之间的关联顺序,选择最好的一种关联方式。(“STRAIGHT_JOIN”则会拒绝 MySQL 优化)
和上面“in”和“exists”比较的结论一样,小表驱动大表才是最优的选择方式!
- 而 MySQL 5.6 版本之前之所以会将“in”子查询修改为“exists”查询是因为使用“in”会在内存或磁盘上中创建临时表,使用这种方式 MySQL 认为不如直接将两个表进行关联,但是这种方式可能会将本来是小表驱动大表的方式误改为大表驱动小表的方式而导致性能低下。
所以当我们看到“selectType”是“dependent subquery”(相关子查询)的时候不要以为这就是最坏的方式,有可能这就是最好的查询方式(比如外查询的结果集很小,内查询能使用索引)。
子查询和连接查询的效率
一般都推荐使用“连接查询”来替代“子查询”:
- “子查询”:
- 不需要表间有字段关联,所以更灵活;(所以“连接查询”都能替换为“子查询”,但“子查询”不一定能替换为“连接查询”)
- 多次遍历数据(笛卡尔集),性能更低;
- “连接查询”:
- 表间必须要有字段关联;
- 一般连接遍历较少,且采用“嵌套循环连接”算法(“NLJ”或“BNL”)减少了内表读取次数,性能更高;
所以对于少数据量时使用“子查询”更为灵活,而大数据量时“连接查询”则更为高效。
而 MySQL 对于子查询也有一些自动优化方式,其中之一就是“半联接”。