索引:索引使用、索引失效
关于
关于索引的基础知识(索引结构:B+树,聚集索引与辅助索引,复合索引,全文索引,索引前缀,回表,排序索引构建:索引的批量加载,索引下推 等),笔记中已有深入了解。
以下记录对“索引使用”、“索引失效”的情况进行说明:
- 什么情况下使用索引?
- 范围查询是否使用索引?
- 什么情况下索引失效?
- 如何进行索引优化?
补:覆盖索引
覆盖索引(covering index):索引包含查询检索到的所有列(查询字段、条件列)。【即:索引覆盖了所有需要的列】
- 即:非主键索引包含所需列,而无需回表。
- 覆盖索引其实是数据库查询优化器的一种机制,而非索引算法或索引实现。
- 覆盖索引是建立在已有索引基础之上的;而要利用覆盖索引进行优化,常常通过复合索引。
- 即从非主键索引中就能得到所需的数据列,而不需要查询主键索引中的记录,避免了回表产生的树搜索所带来的I/O操作,从而提升性能。
- 使用覆盖索引 InnoDB 比 MyISAM 效果更好:InnoDB 使用聚集索引组织数据,如果二级索引中包含查询所需的数据,就不再需要在聚集索引中查找了。【?】
注意:以下情况,执行计划不会选择覆盖查询:
- select 选择的字段中含有不在索引中的字段 ,即索引没有覆盖全部的列。【索引未全面覆盖】
- where 条件中不能含有对索引进行 like 的操作。【?不使用索引?】
示例
有表如下:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` varchar(32) COLLATE utf8_bin NOT NULL COMMENT '名称',
`age` int(3) unsigned NOT NULL DEFAULT '1' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `I_name` (`name`)
) ENGINE=InnoDB;
INSERT INTO student (name, age) VALUES("小赵", 10),("小王", 11),("小李", 12),("小陈", 13);
对应索引结构如下:

对于如下查询:
SELECT age FROM student WHERE name = '小李';
- 通过其普通索引,查询如下:【未使用“覆盖索引”优化】
- 在“name”索引树上找到“小李”对应的节点,获取其“id”为“03”;
- 从主索引树上找到“id”为“03”的叶子节点;【回表】
- 在叶子节的数据中,获取字段命为“age”的值“12”;
- 以上查询,未使用“覆盖索引”,需通过回表在主索引上才能得到“age”值。
- 删除其“name”索引,并以“name”和“age”两个字段建立联合索引:【建立复合索引,以使用“覆盖索引”优化】
ALTER TABLE student DROP INDEX I_name; ALTER TABLE student ADD INDEX I_name_age(name, age);
- 其复合索引结构如下:
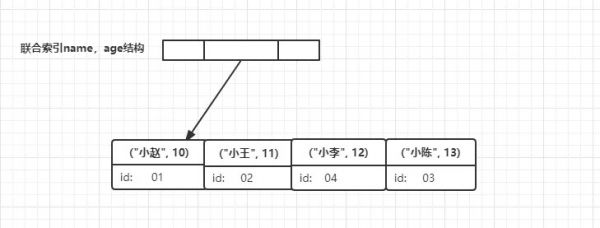
- 通过复合索引,查询流程如下:【使用复合索引】
- 在“name,age”索引树上找到“小李”对应的节点,并在该节点的索引值中获取其“age”为“12”;
- 以上查询,直接从索引中得到“age”值,而并未回表。
- 【“name,age”索引,包括了条件中的“name”字段和查询结果中的“age”字段】

判断“覆盖优化”,通过查询执行计划:

如上,在 explain 的 extra 列可以看到“using index”的信息。
补:Fast Index Creation【???】
在 MySQL 5.5 之前,对于索引的添加或者删除,每次都需要创建一张临时表,然后导入数据到临时表,接着删除原表,如果一张大表进行这样的操作,会非常的耗时,这是一个很大的缺陷。
InnoDB存储引擎从1.0.x版本开始加入了一种“Fast Index Creation”(快速索引创建)的索引创建方式:
- 每次为创建索引的表加上一个S锁(共享锁),在创建的时候,不需要重新建表,删除辅助索引只需要更新内部视图,并将辅助索引空间标记为可用,所以,这种效率就大大提高了。
“Fast Index Creation”与“排序索引构建”?
“Fast Index Creation”是描述修改索引时,表的情况; “排序索引构建”是描述索引构建方式:批量加载,而非单个索引插入;
索引类型
常见的索引类型有:主键索引、唯一索引、普通索引、全文索引、组合索引
- 主键索引:即主索引,根据主键 pk_clolum(length)建立索引,不允许重复,不允许空值;【InnoDB 中即“聚簇索引”】
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
- 唯一索引:用来建立索引的列的值必须是唯一的,允许空值;【只允许一个(行) NULL】
ALTER TABLE 'table_name' ADD UNIQUE index_name('col');
- 唯一索引中使用的列应设置为“NOT NULL”,因为在创建唯一索引时,会将多个空值视为重复值。【?】
- 普通索引:用表中的普通列构建的索引,没有任何限制;
ALTER TABLE 'table_name' ADD INDEX index_name('col');
- 全文索引:用非二进制的大文本对象(char、varchar、text)的列构建的索引;【“倒排索引”设计】
ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col');
- 组合索引:用多个列组合构建的索引,这多个列中的值不允许有空值
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3');
辨析:
- “最左前缀”原则:把最常用作为检索或排序的列放在最左,依次递减。
- mysql 会从左向右匹配直到遇到不能使用索引的条件(>、<、!=、not、like模糊查询的%前缀)才停止匹配;
- 组合索引相当于建立了“col1”、“col1,col2”、“col1,col2,col3”三个索引,而“col2”、“col3”、“col2,col3”或“col1,col3”是不能使用索引的。
- mysql 会从左向右匹配直到遇到不能使用索引的条件(>、<、!=、not、like模糊查询的%前缀)才停止匹配;
- “索引前缀”(前缀索引):在使用组合索引的时候可能因为列名长度过长而导致索引的 key 太大,导致效率降低,在允许的情况下,可以只取列的前几个字符作为索引。
ALTER TABLE 'table_name' ADD INDEX index_name(col1(4),col2(3));
- 表示使用“col1”列的前4个字符和“col2”列的前3个字符作为索引。
索引操作
- 创建:
- “CREATE TABLE”创建表时,指定相应索引。
- “CREATE INDEX”创建索引(普通索引、UNIQUE索引)。【“CREATE INDEX”不能用于创建 PRIMARY KEY 索引】
CREATE INDEX index_name ON table_name (column_list) CREATE UNIQUE INDEX index_name ON table_name (column_list)
- “ALTER TABLE”修改表,可用于表中添加索引(普通索引、UNIQUE索引、PRIMARY KEY索引)。
ALTER TABLE table_name ADD INDEX index_name (column_list) ALTER TABLE table_name ADD UNIQUE (column_list) ALTER TABLE table_name ADD PRIMARY KEY (column_list)
- 删除:
- “DROP INDEX”删除索引。
DROP INDEX index_name ON talbe_name
- “ALTER TABLE”修改表,可用于表中删除索引(普通索引、UNIQUE索引)。
ALTER TABLE table_name DROP INDEX index_name ALTER TABLE table_name DROP PRIMARY KEY
- “DROP INDEX”删除索引。
- 查看:
mysql> show index from tblname; mysql> show keys from tblname;
explain执行计划中的索引
explain 命令用来查看 select 语句执行计划,确认该 SQL 语句有没有使用索引,是否做全表扫描,是否使用覆盖索引等:
id select_type table type possible_keys key key_len ref rows Extra
- “select_type”:SELECT 类型;
- “type”:联接类型;
All | index | range | ref | eq_ref | const | system All:全表扫描 index:全索引扫描 range:有范围的索引扫描 ref_or_null:表关联时,包含 NULL 值的ref【索引包含NULL】 ref:表关联时,最左前缀、非主键和unique的索引扫描【索引无法确定单个行】 eq_ref:表关联时,主键或unique的索引扫描【索引可以确定单个行】 const:索引仅有一个匹配行【所以可以看作常量】 system:系统表【const特例】
- “possible_keys”:可能的索引选择;
- “key”:实际选择的索引;
- “key_len”:所选索引的长度;
- “ref”:索引参考的列;
- “rows”:预计读取的行数;
- “extra”:额外信息;
Using filesort | Using temporary | Using where | Using index condition | Using index
- “Using index”:使用了覆盖索引,速度很快,限于查询字段都位于同一个索引中的场景
- “Using index condition”:表示使用了ICP优化(Index Condition Pushdown,索引条件下推),能减少引擎层访问基表的次数和MySQL Server访问存储引擎的次数
- “Using where”:表示在存储引擎检索行后mysql服务器再进行过滤
- “Using filesort”:返回结果前需要做一次外部排序(内存或硬盘),速度慢应该尽量避免
- “Using temporary”:在对查询结果排序时会使用一个临时表,速度慢
“索引使用”
什么情况下,使用索引:
- 匹配全值。
- 对索引中所有列都指定具体值,即是对索引中的所有列都有等值匹配的条件;
- 匹配值的范围查询。【!!!】
- 对索引的值能够进行范围查找;
- 匹配最左前缀。(组合索引)
- 最左匹配原则可以算是 MySQL 中 B-Tree 索引使用的首要原则。
- 匹配列前缀。
- 仅仅使用索引中的第一列,并且只包含索引第一列的开头一部分进行查找;
- 仅对索引进行查询。
- 当查询的列都在索引的字段中时,查询的效率更高,所以应该尽量避免使用“select *”,需要哪些字段,就只查哪些字段;
- 索引匹配部分精确,而其他部分进行范围匹配。
- 如果列名是索引,那么使用“column_name is null”就会使用索引。
explain select * from t_index where a is null \G
- 经常出现在关键字“order by”、“group by”、“distinct”后面的字段。
- 在“union”等集合操作的结果集字段。
- 经常用作表连接的字段。
- 考虑使用索引覆盖,对数据很少被更新,如果用户经常值查询其中你的几个字段,可以考虑在这几个字段上建立索引,从而将表的扫描变为索引的扫描。
范围查询是否使用索引?
对于范围查询【>,<,>=,<=,!=(<>),not,in(not in),between】,其中:
- 正向查询(<、<=、=、>、>=、between、in)是可以使用索引的;
- 负向查询(not ,not in, not like ,<> ,!= ,!> ,!< ) 不会使用索引;
- 范围查询之后的条件不再使用索引。
注意:
- 对于连续的数值,能用“between”就不要用“in”了。
select id from t where num in(1,2,3) select id from t where num between 1 and 3
- 很多时候(子查询时)用“exists”代替“in”是一个好的选择。【虽然“exists”并不走索引,但子查询中可能用到索引】
select num from a where num in(select num from b) select num from a where exists(select 1 from b where num=a.num)
“in”与“exists”是否使用索引
首先,“in”是范围查询,而“exists”不是范围查询。
- “in”:
- 对于如下语句:
select * from t1 where name in (select name from t2);
- 其执行如下:
for(x in A){ for(y in B){ if(condition is true) {result.add();} } }
- 由上可以看出,对于外层查询,是否使用索引取决于具体情况。【由 MySQL 估计成本,决定是否使用索引】
- “exists”:
- 对于如下语句:
select * from t1 where name exists (select 1 from t2);
- 其执行如下:
for(x in A){ if(exists condition is true){result.add();} }
- 由上可以看出,对于外层查询,是不使用索引的,即对于每一个外层查询的数据都会在子查询中验证是否存在。
- 而“in”与“exists”的查询效率,可能根据 MySQL 版本不同、数据量大小不同而不一。
“order by”是否使用索引?
在某些情况下,MySQL 可以使用索引来满足“order by”子句,并避免执行 filesort 操作(外部排序)时涉及的额外排序。
- 索引不参与排序时,将使用外部排序,extra 显示“Using filesort”;
“order by”将在以下情况使用索引:
- 没有“where”:排序的所有字段,属于同一个索引,属于满足最左前缀;
-- KEY `idx_name_age_pos_phone` (`name`,`age`,`pos`,`phone`) explain select * from user order by name; -- 排序使用索引 explain select * from user order by age,pos; -- 排序不使用索引,而是用filesort(违反最左前缀法则) explain select * from user order by name,created_time; -- 排序不使用索引,而是用filesort(含非索引字段,或不属于同一索引的字段)
- 有“where”:排序与条件的所有字段,属于同一个索引,且“条件字段 + 排序字段”满足最左前缀;
-- KEY `idx_name_age_pos_phone` (`name`,`age`,`pos`,`phone`) explain select * from user where name = 'zhangsan' and age = 20 order by age,pos; -- 排序使用索引 explain select name,age from user where name = 'zhangsan' order by pos; -- 排序不使用索引,而是用filesort(违反最左前缀法则)(但查询仍可使用排序) explain select * from user where name = 'zhangsan' and age = 20 order by created_time,age; -- 排序不使用索引,而是用filesort(含非索引字段,或不属于同一索引的字段)(但查询仍可使用排序)
- 排序中同时使用了“ASC”和“DESC”时,不使用索引;【!!!】
- 在“where”或“order by”中使用了表达式时,不使用索引;
“group by”是否使用索引?
在某些情况下,MySQL 可以使用索引来满足“group by”子句,并避免生成临时表。
- mysql 查询只使用一个索引,因此如果“where”子句中已经使用了索引的话,那么“order by”中的列是不会使用索引的。
- 索引不参与分组时:将使用临时表进行分组,extra 显示“Using temporary”;将使用外部排序,extra 显示“Using filesort”;
- extra 显示“Using index for group-by”说明使用“松散索引扫描”(Loose Index Scan);
“group by”将在以下情况使用索引:
- 没有“where”:分组的所有字段,属于同一个索引,属于满足最左前缀:
KEY `idx_two` (`email`,`age`,`name`) explain select email, age, name from teacher group by email, age, name;
- “distinct”字段组合符合索引最左前缀:
-- KEY `idx_two` (`email`,`age`,`name`) explain select distinct email, age, name from teacher;
- distinct 字段组合起来同样符合索引最左前缀,使用索引 idx_two;
- “min()”/“max()”函数作用于同一列,并且紧跟属于同一索引的分组字段:
KEY `idx_two` (`email`,`age`,`name`) explain select email, min(age), max(age) from teacher group by email;
- email 是分组字段,age 是函数作用字段,email 和 age 组合起来符合 idx_two 最左前缀;
- “count(distinct)”、“avg(distinct)”和“sum(distinct)”组合起来符合最左前缀:
- “avg(distinct)”和“sum(distinct)”中 distinct 只适用单个字段;
- “count(distinct)”中 distinct 适用于多个字段;【松散索引扫描】
KEY `idx_two` (`email`,`age`,`name`) explain select count(distinct email), sum(distinct age) from teacher; explain select count(distinct email, age) from teacher;
- 有“where”:排序与条件的所有字段,属于同一个索引,且“条件字段 + 分组字段”(顺序无要求)满足最左前缀;【紧凑索引扫描】
KEY `idx_two` (`email`,`age`,`name`) explain select email, age, name from teacher where age = 18 group by email, name;
- 分组字段缺少了完整索引中间部分,但由查询条件 age = 18 补充了这部分常量;
KEY `idx_two` (`email`,`age`,`name`) explain select email, age, name from teacher where email = 'kevin@qq.com' group by age, name;
- 分组字段不以索引最左前缀开始,但查询条件 email='kevin@qq.com' 提供了这部分常量;
“松散索引扫描”与“紧凑索引扫描”
通过“松散索引扫描”(Loose Index Scan)和“紧凑索引扫描”(Tight Index Scan)可以高效快速地完成“group by”操作。
【不使用索引】:“group by”操作在没有合适的索引可用的时候,通常先扫描整个表提取数据并创建一个临时表,然后按照“group by”指定的列进行排序。
- 在这个临时表里面,对于每一个 group 的数据行来说是连续在一起的。完成排序之后,就可以发现所有的 groups,并可以执行聚集函数(aggregate function)。可以看到,在没有使用索引的时候,需要创建临时表和排序。(排序:“group by”能够进行隐式或显示排序,但不建议)
- 在执行计划中通常可以看到“Using temporary; Using filesort”。
CREATE TABLE `t1` ( `c1` int(11) DEFAULT NULL, `c2` int(11) DEFAULT NULL, `c3` int(11) DEFAULT NULL, `c4` int(11) DEFAULT NULL, KEY `idx_g` (`c1`,`c2`,`c3`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; mysql> explain extended select c1,c2 from t1 group by c2 \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: index possible_keys: NULL key: idx_g key_len: 15 ref: NULL rows: 15441 filtered: 100.00 Extra: Using index; Using temporary; Using filesort
MySQL建立的索引(B+Tree)通常是有序的,如果通过读取索引就完成“group by”操作,那么就可避免创建临时表和排序。因而使用索引进行“group by”的最重要的前提条件是所有“group by”的参照列(分组依据的列)来自于同一个索引,且索引按照顺序存储所有的 keys(即 BTREE index,而 HASH index 没有顺序的概念)。
MySQ有两种索引扫描方式完成“group by”操作,就是上面提到的松散索引扫描和紧凑索引扫描。
【“松散索引扫描”】:分组操作和范围预测(如果有的话)一起执行完成的。
- 松散索引扫描相当于 Oracle 中的跳跃索引扫描(skip index scan),就是不需要连续的扫描索引中得每一个元组,扫描时仅考虑索引中得一部分。
- 当查询中没有“where”条件的时候,松散索引扫描读取的索引元组的个数和 groups 的数量相同。
- 如果“where”条件包含范围预测,松散索引扫描查找每个 group 中第一个满足范围条件,然后再读取最少可能数的 keys。【???】
- 松散索引扫描只需要读取很少量的数据就可以完成“group by”操作,因而执行效率非常高。
- 使用松散索引扫描需要满足以下条件:【如上节所述】
- 查询在单一表上。
- “group by”指定的所有列是索引的一个最左前缀,并且没有其它的列。
- 如果在选择列表select list中存在聚集函数,只能使用“min()”和“max()”两个聚集函数(如果“min()”和“max()”同时存在则需作用于是同一列)。这一列必须在索引中,且紧跟着“group by”指定的列。
- 如果查询中存在除了“group by”指定的列之外的索引其他部分,那么必须以常量的形式出现(除了“min()”和“max()”两个聚集函数)。
- 索引中的列必须索引整个数据列的值(full column values must be indexed),而不是一个“前缀索引”。
- 自从5.5开始,松散索引扫描可以作用于在“select list”中其它形式的聚集函数:
- “AVG(DISTINCT)”,“SUM(DISTINCT)”和“COUNT(DISTINCT)”可以使用松散索引扫描。
- AVG(DISTINCT), SUM(DISTINCT) 只能使用单一列作为参数。而 COUNT(DISTINCT) 可以使用多列参数。
- 在查询中没有“group by”和“distinct”条件。
- 之前声明的松散扫描限制条件同样起作用。
- “AVG(DISTINCT)”,“SUM(DISTINCT)”和“COUNT(DISTINCT)”可以使用松散索引扫描。
- 在执行计划中通常可以看到“using index for group-by”。
mysql> explain select c1,c2 from t1 group by c1,c2 \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: range possible_keys: NULL key: idx_g key_len: 10 ref: NULL rows: 15442 Extra: Using index for group-by
【“紧凑索引扫描”】方式下,先对索引执行范围扫描(range scan),再对结果元组进行分组。
- 紧凑索引扫描可能是全索引扫描或者范围索引扫描,取决于查询条件。当松散索引扫描条件没有满足的时候,“group by”仍然有可能避免创建临时表。如果在“where”条件有范围扫描,那么紧凑索引扫描仅读取满足这些条件的keys(索引元组),否则执行全索引扫描。这种方式读取所有“where”条件定义的范围内的 keys,或者扫描整个索引,因而称作紧凑索引扫描。对于紧凑索引扫描,只有在所有满足范围条件的 keys 被找到之后才会执行分组操作。
- 如果紧凑索引扫描起作用,那么必须满足:【如上节所述】
- 在查询中存在“where”条件字段(索引中的字段)等于常量,且该字段在“group by”指定的字段的前面或者中间。来自于等于条件的常量能够填充搜索 keys 中的 gaps,因而可以构成一个索引的完整前缀。索引前缀能够用于索引查找。【即:分组字段与条件字段必须构成最左索引(顺序无要求),且字段条件必须是与常量的等式】
- 如果要求对“group by”的结果进行排序,并且查找字段组成一个索引前缀,那么 MySQL 同样可以避免额外的排序操作。
- 在执行计划中通常可以看到“using index”,相当于使用了“覆盖索引”。
mysql> explain extended select c1,c2 from t1 where c1=2 group by c2 \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: ref possible_keys: idx_g key: idx_g key_len: 5 ref: const rows: 5 filtered: 100.00 Extra: Using where; Using index
“索引失效”
索引失效情况:
- MySQL 估计全表扫描比索引开销更小。
- 表太小;
- 结果数据记录占了表总记录的较大比例;
- 不符合“最左前缀”原则。
- 索引列类型不匹配。
- 类型不匹配(包括“varchar”等类型的大小不匹配);
- 在“join”操作中(需要从多个数据表提取数据时),mysql只有在主键和外键的数据类型相同时才能使用索引,否则及时建立了索引也不会使用。
- 数据类型出现隐式转换(如:字符串值未使用单引号);
--(age :varchar) where age = 30 -- 使用索引 where 'age' = '30' -- 使用索引 where 'age' = 30 -- 不使用索引
- 类型不匹配(包括“varchar”等类型的大小不匹配);
- 索引列为表达式:
- 索引列参与计算;
where a = 10 - 1 -- 使用索引 where a + 1 = 10 -- 不使用索引
- 索引列上使用了函数;
where DAY(column) = ...
- 索引列参与计算;
- “like”操作以“%”为前缀。(不恰当的模糊匹配)
- “like %keyword”:可以通过翻转函数优化。
- 用“or”分割开的条件,如果“or”前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
- 即,“or”前后的字段都必须具有索引。否则,可以考虑使用“union”替换:
select * from dept where dname='jaskey' or loc='bj' or deptno=45 -- 使用 union 替换 select * from dept where dname='jaskey' union select * from dept where loc='bj' union select * from dept where deptno=45
- 负向查询(not ,not in, not like ,<> ,!= ,!> ,!< ) 。
索引优化
存储引擎对索引的优化
Multi-Range Read(MRR 多范围读取)
MySQL 5.6 开始支持,这种优化的目的是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问。
- 这种优化适用于 range、ref、eq_ref 类型的查询。
Multi-Range Read 优化的好处:
- 让数据访问变得较为顺序。
- 减少缓冲区中页被替换的次数。
- 批量处理对键值的查询操作。
可以使用参数“optimizer_switch”中的标记来控制是否开启 Multi-Range Read 优化。下面的方式将设置为总是开启状态:
SET @@optimizer_switch='mrr=on,mrr_cost_based=off';
Index Condition Pushdown(ICP 索引条件下推)
MySQL 5.6 开始支持,不支持这种方式之前,当进行索引查询时,首先我们先根据索引查找记录,然后再根据 where 条件来过滤记录。然而,当支持 ICP 优化后,MySQL 数据库会在取出索引的同时,判断是否可以进行 where 条件过滤,也就是将 where 过滤部分放在了存储引擎层,大大减少了上层SQL对记录的索取。
- ICP 支持 range、ref、eq_ref、ref_or_null 类型的查询,当前支持 MyISAM 和 InnoDB 存储引擎。
可以使用下面语句开启ICP:
set @@optimizer_switch = "index_condition_pushdown=on"
复制代码或者关闭:
set @@optimizer_switch = "index_condition_pushdown=off"
复制代码当开启了 ICP 之后,在执行计划 Extra 可以看到“Using index condition”提示。
like 模糊查询的优化
模糊查询的三种情况:
- “like keyword%”:索引有效。
- “like %keyword”:索引失效,但可以通过翻转函数优化。【???】
where i.C_LCN_NO like '%245' -- 使用索引 where reverse(i.C_LCN_NO) like reverse('%245') -- 使用索引
- “like %keyword%”:索引失效,且不能通过翻转函数优化。
模糊查询的替代方式:
- 使用下面的函数来进行模糊查询,如果出现的位置 > 0,则表示包含该字符串。查询效率比 like 要高。
- “LOCATE(substr,str)”:
- 返回子串 substr 在字符串 str 中第一次出现的位置,没有则返回 0。
SELECT * FROM t_blog t WHERE LOCATE("xxx",t.field) > 0
- “POSITION(substr IN str)”:
- 返回子串 substr 在字符串 str 中第一次出现的位置,没有则返回 0。【position 是 locate 的别名】
SELECT * FROM t_blog t WHERE POSITION("xxx" IN t.field) > 0
- “INSTR(str,substr)”:
- 返回子串 substr 在字符串 str 中第一次出现的位置,没有则返回 0。【与 LOCATE() 形式相同,参数顺序相反】
SELECT * FROM t_blog t WHERE INSTR(t.field,"xxx") > 0
Limit 分页的优化
limit 的用法是limit [offset], [rows],其中“offset”表示偏移值,“rows”表示需要返回的数据行。
- limit 给分页带来了极大的方便,但数据偏移量一大,limit 的性能就急剧下降。
如以下语句:
select * from table_name where( user = xxx ) limit 1000000,30
扫描满足条件的 1000030 行,扔掉前面的 1000000 行,然后返回最后的30行。其执行:
- 从数据表中读取第 N 条数据添加到数据集中;
- 重复第一步直到 N = 1000000 + 30;
- 根据 offset 抛弃前面 1000000 条数;
- 返回剩余的 30 条数据;
其实会读取 1000030 行数据,而非直接定位到第 1000030 行,而每一行的读取数据,都涉及到辅助索引到聚集索引的回表,由此产生大量的I/O操作,所以在数据量大的时候,显然地操作缓慢。
- (如果其不使用辅助索引,而是聚集索引的条件,则没必要优化)
所以其优化思路在于:
- 如何直接定位到偏移位置的数据?
- 如何使用辅助索引而避免回表?
其优化方式:
- 子查询的分页方式:
- 先查找出需要数据的索引列,再通过索引列查找出需要的数据;如下:
Select * From table_name Where id in (select id from table_name where ( user = xxx ) limit 1000000,30);- 如上语句:
- 子查询只用到了 user 索引,没有取实际的数据则不涉及回表,所以不涉及到磁盘IO,所以即使是比较大的 offset 查询速度也不会太差。(或覆盖索引,也无回表)
- 外部查询转化为基于主键(id)的搜索,且获得了准确索引值,所以查询过程也相对较快。
- JOIN分页方式:
- 再子查询的基础上,使用 join 替代 in:
select * from table_name inner join ( select id from table_name where (user = xxx) limit 1000000,30) b using (id);- 大数据量上,join 相对于 in 的效率更高;
索引设计原则
- 最左前缀匹配原则。
- “=”和“in”可以乱序。
- 比如“a = 1 and b = 2 and c = 3 ”建立“(a,b,c)”索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式;
- 尽量选择区分度高的列作为索引。【区分度:count(distinct col)/count(*)】
- 区分度在 80% 以上的时候就可以建立索引;
- 索引列不能参与计算,保持列“干净”。
- 比如“from_unixtime(create_time) = '2014-05-29'”就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成“create_time = unix_timestamp(’2014-05-29’)”;
- 尽量的扩展索引,而不要新建索引。
- 定义有外键的数据列一定要建立索引。
- 对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
- 对于定义为“text”、“image”和“bit”的数据类型的列不要建立索引。
- 因为这些列的数据量要么相当大,要么取值很少。
- 对于经常存取的列避免建立索引。
- 依据索引使用、索引失效的情况,在使用中进行优化。
- mysql查询只使用一个索引,因此如果“where”子句中已经使用了索引的话,那么“order by”中的列是不会使用索引的。