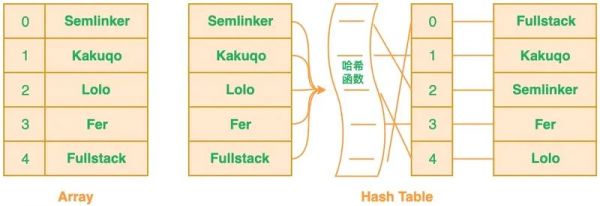
什么是布隆过滤器(BloomFilter)?
Eijux(讨论 | 贡献)2021年5月12日 (三) 01:42的版本 (建立内容为“category:Rediscategory:数据结构 == 关于 == 布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的'''二…”的新页面)
关于
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。
布隆过滤器可以用于检索一个元素是否可能在一个集合中。
- 优点:空间效率和查询时间都比一般的算法要好的多,
- 缺点:有一定的误识别率,不能删除。
- 其变种“Counting Bloom filter”可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。
通常判断某个元素是否存在用的是什么?
HashMap!
- 将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。

但是 HashMap 的实现也有缺点,例如存储容量占比高:
- 考虑到负载因子的存在,通常空间是不能被用满的,而数据量大的时候,HashMap 占据的内存大小就变得很可观了。
由此就需要一种查询效率近似 HashMap,但空间占用更少的结构来进行大数据量的判断。
原理
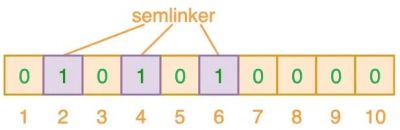
布隆过滤器是一个 bit 向量或者说 bit 数组(仅包含 0 或 1 值):

要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并将每个哈希值所指向的 bit 位置为 1:
- 如下,添加元素“semlinker”:
- 如下,添加元素“kakuqo”:
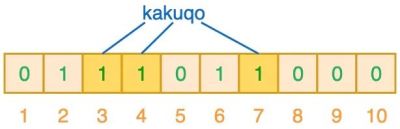


在进行元素判定时,同样通过多个哈希函数生成多个哈希值,并查找哈希值所指向的 bit 位:
- 如下,查找元素“semlinker”:
- 如下,查找元素“fullstack”:
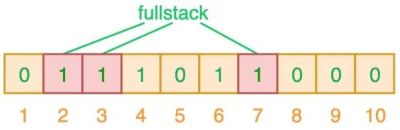
- 查找元素“bullshit”:
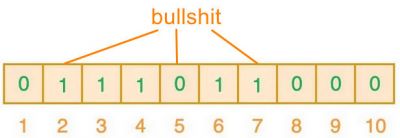


可以看出,判定结果为:元素“semlinker”、“fullstack”都在集合中,“bullshit”不在集合中。
但是其实“fullstack”并不在其中,是误报。
- 产生误报的原因是由于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。
如上,可以看出 Bloom Filter 的判定结果:
- 哈希值比特位都为 1,元素可能在集合中;
- 哈希值比特位有 0,元素一定不在集合中。
即,布隆过滤器用于检索一个元素是否可能在一个集合中。
“哈希函数个数”(k)和“布隆过滤器长度”(m)
哈希函数个数 与 布隆过滤器长度 直接影响 Bloom Filter 的效率:
- 布隆过滤器的长度会直接影响误报率:布隆过滤器越长其误报率越小。
- 布隆过滤器长度过小,则很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了;
- 哈希函数的个数则需要在效率与误报率间平衡:
- 个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
以:k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率,其关系如下: