核心技术Ⅱ:I/O
输入/输出流
- 在 Java API 中:
- 输入流:可以从其中读入一个字节序列的对象;
- 输出流:可以向其中写入一个字节序列的对象;
- 使用方法的不同:
- 字节流:抽象类“InputStream”和“OutputStream”构成了I/O类层次结构的基础;
- (不便于处于Unicode形式存储的信息)
- 字符流:抽象类“Reader”和“Writer”构成的专门用于处理“Unicode”字符的单独的类层次结构;
- (读写操作基于两字节的Char值,即Unicode码元,而非基于byte值)
- 字节流:抽象类“InputStream”和“OutputStream”构成了I/O类层次结构的基础;
- 输入/输出,都是相对于内存理解。
- 何时使用字节流、何时使用字符流?
- 字节流操作的基本单元为字节;字符流操作的基本单元为Unicode码元。
- 字节流默认不使用缓冲区;字符流使用缓冲区。
- 字节流通常用于处理二进制数据(实际上它可以处理任意类型的数据,但不支持直接写入或读取Unicode码元);字符流通常处理文本数据,支持写入及读取字符(Unicode码元)。
读写字节
- “abstract int read()”方法:(“InputStream”类的抽象方法)读入一个字节,并返回读入的字节,或者在遇到输入源结尾时返回“-1”;
- (继承于InputStream的具体输入流类,必须覆盖这个方法以提供适用的功能)
- (InputStream 类还有若干个非抽象的方法,可以读入一个字节数组,或者跳过大量的字节。这些方法都要调用抽象的“read”方法,因此,各个子类都只需覆盖这一个方法)
- “int read(byte[] b)”:用于读入一个字节数组;
- “abstract void write()”方法:(“OutputStream”类的抽象方法)向某个输出位置写出一个字节;
- (“write”与“read”类似,被其他方法调用,具体输出类需要实现该方法)
- “void write(byte[] b)”:用于写出一个字节数组;
- “write”与“read”方法,在执行时都将阻塞,直到字节处理完毕;
- “available”方法:检查当前可读入的字节数量:
- 则,以下代码片段不能被阻塞:
int bytesAvailable = in.available(); if (bytesAvai1able > 0) { byte[] data = new byte[bytesAvai1able]; in.read(data); }
- “flush”方法:刷新输出流的缓冲区;
- “close”方法:关闭输入/输出流,释放系统资源;
- (关闭一个输出流的同时还会冲刷用于该输出流的缓冲区)
- 如果不关闭文件,那么写出字节的最后一个包可能将永远也得不到传递。
- 【一般使用众多的从基本的“InputStream”和“OutputStream”类导出的某个输入/输出类,而不只是直接使用字节。】
- (数据可能包含数字、字符串和对象,而不是原生字节)
相关方法
java.io.InputStream1.0
- abstract int read()
- 从数据中读人一个字节,并返回该字节。这个 read 方法在碰到输入流的结尾时返回 -1
- int read(byte[] b)
- 读入一个字节数组,并返同实际读入的字节数,或者在碰到输人流的结尾时返同 -1,这个 read 方法最多读入 b.1ength 个字节。
- int read(byte[] b, int off, int len)
- 读入个字节数组。这个 read 方法返回实际读入的字节数, 或者在碰到输入流的结尾时返回-1
- 参数 : b 数据读入的数组
- off 第一个读入字节应该被放置的位置在 b 中的偏移量
- len 读入字节的最大数量
- long skip(long n)
- 在输入流中跳过n个字节,返回实际跳过的字节数(如果碰到输入流的结尾,则可能小于n)。
- int available()
- 返回在不阻塞的情况卜可获取的字节数(回忆一下,阻塞意味着当前线程将失去它对资源的占用)。
- void close()
- 关闭这个输入流。
- void mark(int readlimit)
- 在输入流的当前位置打一个标记(并非所有的流都支待这个特性。如果从输入流中已经读入的字节多于readlimit个,则这个流允许忽略这个标记。
- void reset()
- 返回到最后一个标记,随后对 read 的调用将重新读入这些字节。如果当前没有任何标记,则这个流不被重置。
- boolean markSupported()
- 如果这个流支持打标记,则返回true。
java.io.OutputStream 1.0
- abstract void write(int n)
- 写出一个字节的数据。
- void write(byte[] b)
- void write(byte[J b, int off, int len)
- 写出所有字节或者某个范围的字节到数组b中 。
- 参数 : b 数据读入的数组
- off 第一个读入字节应该被放置的位置在 b 中的偏移量
- len 读入字节的最大数量
- void close()
- 冲刷并关闭输出流。
- void flush()
- 冲刷输出流,也就是将所有缓冲的数据发送到目的地。
流家族
- 输入流与输出流的层次结构:
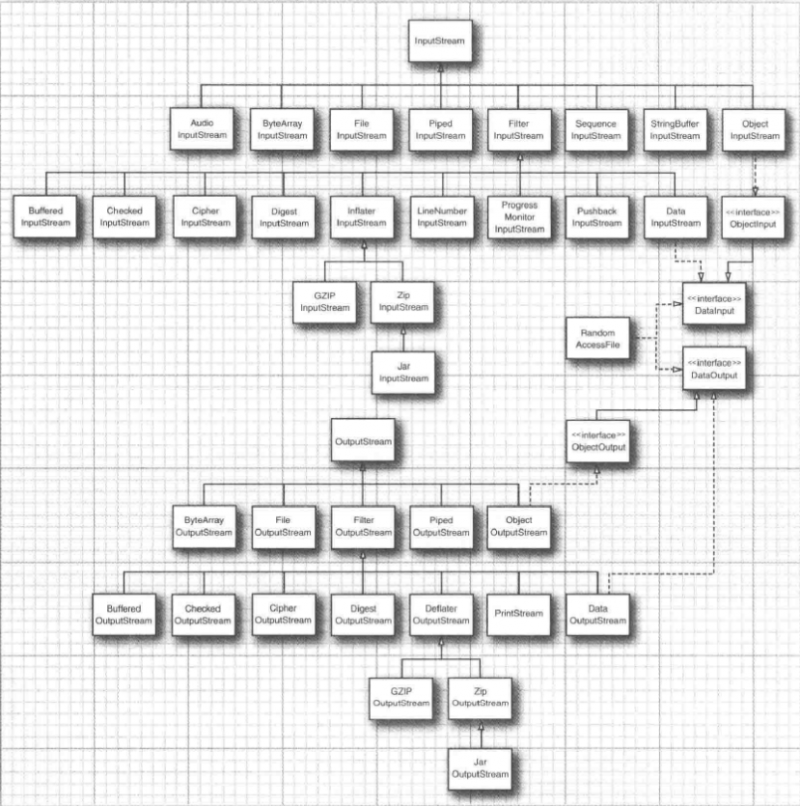
- 要想读写字符串和数字,就需要功能更强大的子类,如:
- “DataInputStream”和“DataOutputStream”可以以二进制格式读写所有的基本Java类型;
- “ZipInputStream”和“ZipOutputStream”可以以常见的ZIP压缩格式读写文件;
- Reader和Writer的层次结构:
- 附加接口:
- “Closeable”:
void close() throws IOException- (“InputStream”、“OutputStream”、“Reader”和“Writer”都实现了“Closeable”接口)
- (“java.io.Closeable”接口扩展了“java.lang.AutoCloseable”接口,因此,对任何“Closeable”进行操作时,都可以使用“try-with-resource”语句)
- (“java.io.Closeable”抛出“IOException”;“java.lang.AutoCloseable”可以抛出任意异常)
- “Flushable”:
void flush()- (“OutputStream”和“Writer”还实现了“Flushable”接口)
- “Readable”:
int read(CharBuffer cb)
- “Appendable”:
// 添加单个字符 Appendable append(char c) // 添加字符序列 Appendable append(CharSequence s)- 只有“Writer”实现了“Appendable”;



【CharBuffer、CharSequence、String、StringBuilder、StringBuffer】
CharBuffer、CharSequence、String、StringBuilder、StringBuffer
组合输入/输出流过滤器
Java 使用了一种灵巧的机制来分离这两种职责:
- 某些输入流(如“FileInputStream”和由 URL 类的“openStream”方法返回的输入流)可以从文件和其他更外部的位置上获取字节,
- 而其他的输入流(如“DatainputStream”) 可以将字节组装到更有用的数据类型中。
Java 程序员必须对二者进行组合,通过嵌套过滤器来添加多重功能。
例如:
- 为了从文件中读入数字,首先需要创建一个FileinputStream,然后将其传递给“DataInputStream”的构造器:
FileinputStream fin = new FileinputStream("employee.dat"); DataInputStream din = new DataInputStream(fin); doub1ex = din.readDouble();
- 使用缓冲机制,以及用于文件的数据输入方法:
DataInputStream din = new DataInputStream( new BufferedinputStream( new Fi1eInputStream("emp1oyee.dat")));
- 跟踪各个中介输入流(当读人输入时,预览下一个字节,以了解它是否是你想要的值):
- (读入和推回是可应用于可回推(pushback)输入流的仅有的方法)
PushbackInputStream pbin = new PushbackInputStream( new BufferedlnputStream( new FilelnputStream("employee.dat"))); // 预读下一个字节: int b = pbin.read(); // 并非期望值时将其推回流中 if(b != '<') pbin.unread(b);
- 预先浏览并且还可以读入数字(需要一个既是可回推输入流,又是一个数据输入流的引用):
DataInputStream din = new DataInputStream( pbin = new PushbackInputStream( new BufferedInputStream( new Fi1eInputStream("emp1oyee.dat"))));
- 从一个ZIP 压缩文件中通过使用下面的输入流序列来读入数字:
ZipInputStream zin = new ZipInputStream(new Fi1eInputStream("emp1oyee.zip")); DataInputStream din = new DataInputStream(zin);
文本输入/输出(文本即字符)
在存储文本字符串时,需要考虑字符编码(character encoding)方式。
- 在 Java 内部使用的“UTF-16”编码方式中,字符串“1234”编码为“00 31 00 32 00 33 00 34”(十六进制)。但是,以“UTF-8”编码方式中为“4A 6F 73 C3 A9”;
文本:输入(“PrintWriter”)/输出(“Scanner”)
写出文本
“PrintWriter”:文本格式打印字符串和数字;
- 它有一个将“PrintWriter”链接到“FileWriter”的便捷方法:
PrintWriter out = new PrintWriter("employee.txt", "UTF-8"); // 等同于 PrintWriter out = new PrintWriter(new Fi1eOutputStream("employee.txt"), "UTF-8");
- 需要使用与“System.out”类似的“print、println”和“printf”方法;
- (可以用这些方法来打印数字:int、short、1ong、float、double,字符,boolean值,字符串,及对象)
- 如果写出器为自动冲刷模式,则每次调用“println”时,缓冲区中的字符都会被发送到目的地(打印写出器总是带缓冲区的);
- (自动冲刷机制,默认禁用)
PrintWriter out = new PrintWriter( new OutputStreamWriter( new Fi1eOutputStream("employee.txt"), "UTF-8"), true); // auto flash
- “print”方法不抛出异常,可以调用“checkError”方法来杳看输出流是否出现了某些错误;
- 关于行结束符:
- Windows 系统是“\r\n”;UIX 系统是“\n”;
- 可以通过“System.getProperty("line.separator")”获得目标系统行结束符;
- “println”方法在行中添加了对目标系统来说恰当的行结束符;
读入文本
读入文本方式:
- 最简单的任意文本处理:“Scanner”类;【见[1]】
// 通过输入流构造“Scanner”对象 Scanner in = new Scanner(System.in); // 读取输入行 String name = in.nextLine(); // 读取字符串(以空格符作为分隔) String firstName = in.next(); // 读取整数 int age = in.nextInt(); //读取浮点数 double salary = in.nextDouble();
- 短文本:(直接读取到一个字符串)
String content = new String(Files.readAllBytes(path), charset);
- 文本按行读入:(读取到一个字符串集合)
List<String> 1ines = Files.readAllLines(path,charset);
- 长文本:(利用流“Stream<String>”)
try (Stream<String> lines = Files.lines(path, charset)) { . . . }
- (Java早期版本)通过“BufferReader”类:
InputStream inputStream = . . . ; try (BufferedReader in = new BufferedReader(new InputStreamReader(inputStream, StandardCharsets.UTF_8))) { String line; while ((line = in.readline()) != null) { // do something with line } }
- “BufferedReader”类有一个“lines”方法,可以产生一个“Stream<String>”对象。
- “BufferedReader”与“Scanner”不同,没有任何用于读入数字的方法。
【转换流】
转换流:(在“字节流”与“字符流中转换”)
- “OutputStreamWriter”:将使用选定的字符编码方式,把 Unicode 码元的输出流转换为字节流。
- 继承于“Writer”,是字符流通向字节流的桥梁;【写出:字符 -> 字节】
- “InputStreamReader”:将包含字节(用某种字符编码方式表示的字符)的输入流转换为可以产生 Unicode 码元的读入器。
- 继承于“Reader”,是字节流通向字符流的桥梁;【读入:字节 -> 字符】
Reader in = new InputStreamReader(System.in); Reader in = new InputStreamReader(new Fi1eInputStream("data.txt"), StandardCharsets.UTF_8);
- 【“字节流”用于输出输出;“字符流”:用于代码中操作】
- 应用如“基于Socket的聊天系统”:“字节流”用于传输;“字符流”在客户端显示;
- “OutputStreamWriter”与“InputStreamReader”属于字符流“Reader/Writer”结构层次;
【缓冲字符高级流:“BufferedWriter”和“BufferedReader”】
- 以“行”作为单位,进行读取/写出;
- “BufferedReader”是“缓冲字符输入流”;
- “BufferedWriter”是“缓冲字符输出流”;
【“OutputStreamWriter”、“PrintWriter”与“BufferedWriter”】
| OutputStreamWriter | PrintWriter | BufferedWriter |
|---|---|---|
|
|
|
- 需要字节流转换为字符流时使用“OutputStreamWriter”;需要文本输出使用“PrintWriter”;
字符编码方式
Java 针对字符使用的是 Unicode标准,有多种不同的字符编码方式:
- “UTF-8”:(最常用)
- 将每个Unicode编码点编码为1到4个字节的序列。(好处是ASCII字符集中的每个字符都只会占用一个字节)
- “UTF-16”:(Java字符串中使用的编码方式)
- 将每个Unicode编码点编码为1个或2个16位值。(分为“高位优先”和“低位优先”两种形式,通过文件的“字节顺序标记”来确定)
- UTF-8编码的文件不需要字节顺序标记;
“StandardCharsets”类具有类型为“Charset”的静态变量,用于表示每种Java虚拟机都必须支持的字符编码方式:
- StandardCharsets.UTF_8
- StandardCharsets.UTF_16
- StandardCharsets.UTF_16BE
- StandardCharsets.UTF_16LE
- StandardCharsets.IS0_8859_1
- StandardCharsets.US_ASCII
- 为了获得另一种编码方式的“Charset”, 可以使用静态的“forName”方法:
Charset shiftJIS = Charset.forName("Shift-JIS");
- 在读入或写出文本时,应该使用“Charset”对象:
// 将一个字节数组转换为字符串 String str = new String(bytes, StandardCharsets.UTF_8);
- “Charset.defaultCharset”:静态方法,返回平台使用的编码方式;
- “Charset.availableCharsets”:静态方法,返回所有可用的“Charset”实例;
- 在不指定任何编码方式时,有些方法会使用默认的平台编码方式(如“String(byte[])”构造器),而其他方法会使用UTF-8(例如“Files.readAlllines”) 。
- Oracle的Java实现有一个用于覆盖平台默认值的系统属性“file.encoding”,但并非官方支持的属性,不应使用。
读写二进制数据
DataInput 和 DataOutput 接口
“DataOutput”接口定义了下面用于以二进制格式写数组、字符、boo l e an 值和字符串的方法:(“DataInput”接口类似)
- writeChars
- writeByte
- writeInt
- writeShort
- writeLong
- writeFloat
- writeDouble
- writeChar
- writeBoo1ean
- writeUTF:(使用修订版的8位Unicode转换格式写出字符串,与直接使用标准的UTF-8编码方式不同)
- 应该:只在写出用于Java虚拟机使用的字符串时,才使用“writeUTF”方法
如,“writeInt”总是将一个整数写出为4 字节的二进制数量值,而不管它有多少位。
- 对于给定类型的每个值,所需的空间都是相同的,将其读回也比解析文本要更快。
- (类型占用空间大小、存储方式等,是由处理器类型决定的,所以带来了跨平台的问题)
- (在Java中,所有的值都按照高位在前的模式写出,而不管使用何种处理器,这使得Java 数据文件可以独立于平台)
为了以二进制操作文件内容,可以将“DataInputStream/DataOutputStream”与某个字节源相组合:
DataInputStream in = new DataInputStream(new FileInputStream("emp1oyee.dat")); DataOutputStream out = new DataOutputStream(new FileOutputStream("employee.dat"));
随机访问文件(“RandomAccessFile”)
“RandomAccessFile”类,可以在文件中的任何位置查找或写入数据。
- (磁盘文件都是随机访问的,但是与网络套接字通信的输入/输出流却不是)
- 通过使用字符串“r”(用于读入访问)或“rw”(用于读入/写出访问)
RandomAccessFile in= new RandomAccessFile("employee.dat", "r");
RandomAccessFile inOut = new RandomAccessFile("employee.dat", "rw");
- 将已有文件作为“RandomAccessFile”打开时,这个文件并不会被删除。
- “seek”方法:用于将文件指针设置到文件中的任意字节位置(参数类型位“long”)。
- “getFilePointer”方法:将返回文件指针的当前位置。
- “RandomAccessFile”类同时实现了“DataInput”和“DataOutput”接口。为了读写随机访问文件,可以使用前小节中的“readInt”/“writeInt”和“readChar”/“writeChar”之类的方法。
ZIP 文档
ZIP文档以压缩格式存储了一个或多个文件,每个ZIP 文档都有一个头,包含诸如每个文件名字和所使用的压缩方法等信息。
“ZipInputStream”用于读入ZIP文档:
- “getNextEntry”:返回一个描述这些项的 ZipEntry 类型的对象;
- “getInputStream”:传递该项可以获取用于读取该项的输入流;
- “closeEntry”:读入下一项;
ZipInputStream zin = new ZipInputStream(new FileInputStream(zipname)); ZipEntry entry; while ((entry = zin.getNextEntry()) != null) { InputStream in = zin.getInputStream(entry); // read the contents of "in" . . . zin.closeEntry(); } zin.close();
“ZipOutputStream”用于写出到ZIP文件:
- 创建一个“ZipEntry”对象;
- (ZipEntry的构造器将设置其他诸如文件日期和解压缩方法等参数,可覆盖这些设置)
- “putNextEntry”:写出新文件;
- “closeEntry”:完成写操作;
Fi1eOutputStream fout = new FileOutputStream("test.zip"); ZipOutputStream zout = new ZipOutputStream(fout); // for all files { ZipEntry ze = new ZipEntry(filename); zout.putNextEntry(ze); // send data to zout . . . zout.closeEntry(); } zin.close();
- JAR 文件只是带有一个特殊项(清单)的 ZIP 文件(可以使用“JarInputStream”和“JarOutputStream”类来读写清单项)。
相关方法
java.util.zip.ZipInputStream 1.1
- ZipInputStream(InputStream in)
- 创建一个 ZipInputStream,使得我们可以从给定的 InputStream 向其中填充数据。
- ZipEntry getNextEntry()
- 为下一项返回 ZipEntry 对象,或者在没有更多的项时返回null。
- void closeEntry()
- 关闭这个 ZIP 文件中当前打开的项。之后可以通过使用 getNextEntry() 读入下一项。
java.util.zip.ZipIOnputStream 1.1
- ZipIOnputStream(OutputStream out)
- 创建一个将压缩数据写出到指定的 OutputStream 的 ZipOutputStream。
- void putNextEntry(ZipEntry ze)
- 将给定的 ZipEntry 中的信息写出到输出流中,并定位用于写出数据的流,然后这些数据可以通过write()写出到这个输出流中。
- void closeEntry()
- 关闭这个ZIP文件中当前打开的项。 使用 putNextEntry 方法可以开始下一项。
- void setLevel(int level)
- 设置后续的各个DEFLATED项的默认压缩级别。 这里默认值是 Deflater.DEFAULT_ COMPRESSION。 如果级别无效, 则抛出IllegalArgumentException。
- 参数: 1evel 压缩级别,从 O(NO_COMPRESSION)到9(BEST_COMPRESSION)
- void setMethod (int method)
- 设置用于这个ZipOutputStream的默认压缩方法,这个压缩方法会作用于所有没有指定压缩方法的项上。
- 参数:method 压缩方法, DEFLATED 或 STORED
java.util.zlp.ZipEntry 1.1
- ZipEntry(String name)
- 用给定的名字构建一个Zip项。
- 参数:name 这一项的名字
- 1ong getCrc()
- 返回用千这个ZipEntry的CRC32校验和的值。
- String getName()
- 返回这一项的名字。
- long getSize()
- 返回这一项未压缩的尺寸, 或者在未压缩的尺寸不可知的情况下返回-1。
- boolean isDirectory()
- 当这一项是目录时返回true。
- void setMethod(int method)
- 参数:method 用于这一项的压缩方法, 必须是 DEFLATED 或 STORED
- void setSize(long size)
- 设置这一项的尺寸,只有在压缩方法是 STORED 时才是必需的。
- 参数: size 这一项未压缩的尺寸
- void setCrc(1ong crc)
- 给这一项设置CRC32校验和,这个校验和是使用CRC32类计算的。只有在压缩方法是STORED时才是必需的。
- 参数: crc 这一项的校验和
java.util.zip.ZipFile 1.1
- ZipFile(String name)
- ZipFile(File file)
- 创建一个 ZipFile, 用于从给定的字符串或 File 对象中读入数据。
- Enumeration entries()
- 返回一个 Enumeration 对象, 它枚举了描述这个 ZipFile 中各个项的 ZipEntry 对象。
- ZipEntry getEntry(String name)
- 返回给定名字所对应的项,或者在没有对应项的时候返回 null。
- 参数: name 项名
- InputStream getinputStream(ZipEntry ze)
- 返回用于给定项的 InputStream。
- 参数: ze 这个 ZIP 文件中的一个 ZipEntry
- String getName()
- 返回这个ZIP文件的路径。
对象输入/输出流与序列化
Java 语言支持一种称为对象序列化 (object serialization) 的非常通用的机制,它可以将任何对象写出到输出流中,并在之后将其读回。
(对象序列化是以特殊的文件格式存储对象数据的)
保存和加载序列化对象
“ObjectOutputStream”:保存对象数据。(“writeObject”方法)
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("employee.dat"));
Employee harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
Manager boss = new Manager("Carl Cracker", 80000, 1987, 12, 15);
out.writeObject(harry);
out.writeObject (boss);
“ObjectinputStream”:读取对象数据。(“readObject”方法)
ObjectlnputStream in = new ObjectlnputStream(new FilelnputStream("employee.dat"));
Employee el = (Employee) in.readObject();
Employee e2 = (Employee) in.readObject();
- 需要保存对象的类必须实现“Serializable”接口:(“Serializable”接口没有任何方法)
保存“对象网络”:当一个对象被多个对象共享,作为它们各自状态的一部分时,每个对象都是用一个序列号(serial number)保存的。
保存对象时:
- 对遇到的每一个对象引用都关联一个序列号;
- 对于每个对象:
- 当第一次遇到时,保存其对象数据到输出流中;
- 如果已被保存过,那么只写出“与之前保存过的序列号为x的对象相同”;
读取对象时:
- 对于对象输入流中的对象:第一次遇到其序列号时,构建它,并使用流中数据来初始化它,然后记录这个顺序号和新对象之间的关联;
- 当遇到 “与之前保存过的序列号为x的对象相同”标记时,获取与这个序列号相关联的对象引用;
实例:

代码:
package objectStream; import java.io.*; class ObjectStreamTest { puolic static void main(String [] args) throws IOException, ClassNotFoundException { Employee harry = new Employee("Harry Hacker", 50000, 1989, 10, 1); Manager carl = new Manager("Carl Cracker", 80000, 1987, 12, 15); carl .setSecretary(harry); Manager tony= new Manager("Tony Tester", 40000, 1990, 3, 15); tony. setSecretary(harry); Employee[] staff = new Employee[3]; staff[O] = carl; staff[l] = harry; staff[2] = tony; // save a11 emp1oyee records to the fi1e emp1oyee.dat try (ObjectOutputStream out = new ObjectOutputStream(new Fi1eOutputStream("employee.dat"))) { out.writeObject(staff); } try (ObjectInputStream in= new ObjectInputStream(new FileInputStream("employee.dat"))) { // retrieve all records into a new array Employee[] newStaff = (Employee[)) in.readObject(); // raise secretary's salary newStaff[l].raiseSalary(lO); // print the newly read employee records for (Employee e : newStaff) System.out.println(e); } } }
对象序列化的文件格式【了解】
修改默认的序列化机制
防止域被序列化
Java 拥有一种很简单的机制来防止域被实例化:将域标记为“transient”。
- 某些数据域是不可以序列化的,在重新加载对象或将其传送到其他机器上时都是没有用处的;
- 某些域属于不可序列化的类,也需要将它们标记成“transient”;
修改序列化默认读写
可序列化的类可以定义具有下列签名的方法:
private void readObject(ObjectinputStream in)
throws IOException, ClassNotFoundException;
private void wri teObj ect(Obj ectOutputStream out)
throws IOException;
之后,数据域就再也不会被自动序列化,取而代之的是调用这些方法。
示例:
public class LabeledPoint implements Serializable
{
private String label;
private transient Point2D.Doub1e point; // 不可序列化
...
private void writeObject(ObjectOutputStream out) throws IOException
{
// 调用该方法,写出对象描述符,和 String域的1abel
out.defaultWriteObject();
// 写出不可序列化的point
out.writeDouble(point.getX());
out.writeDouble(point.getY()) ;
}
private void readObject(ObjectInputStream in) throws IOException
{
// 调用该方法,读入对象描述符,和1abel域
in.defaultReadObject();
// 读入不可序列化的point
doub1e x = in.readDoub1e();
double y = in.readDoub1e();
point = new Point2D.Double(x, y);
}
}
自定义序列化机制
自定义序列化,类必须实现“Externalizable”接口,并定义两个方法:
public void readExterna1(ObjectInputStream in)
throws IOException, ClassNotFoundException;
pub1ic void writeExternal(ObjectOutputStream out)
throws IOException;
这些方法对包括超类数据在内的整个对象的存储和恢复负全责。
- “readObject”和“writeObject”方法是私有的,并且只能被序列化机制调用。
- “readExternal”和“writeExternal”方法是公共的。(“readExternal”还潜在地允许修改现有对象的状态)
示例:
public class Employee implements Externalizable
{
private String name;
private Double salary;
private LocalDate hireOay;
...
private void writeExterna1(ObjectOutput s) throws IOException
{
name = s.readUTF();
salary = s.readDouble();
hireDay = LocalDate.ofEpochDay(s.readLong());
}
private void readExternal(ObjectInput s) throws IOException
{
s.writeUTF(name);
s.writeDouble(salary);
s.writeLong(hireDay.toEpochDay());
}
}
序列化单例和类型安全的枚举
在序列化和反序列化时,如果目标对象是唯一的(“单例”和“类型安全的枚举”),默认的序列化机制是不适用的:
- (使用Java语言的“enum”结构,不必担心序列化)
- 记住向遗留代码中所有类型安全的枚举以及向所有支持单例设计模式的类中添加“readResolve”方法;
如有:
public class Orientation { public static final Orientation HORIZONTAL = new Orientation(l); public static final Orientation VERTICAL = new Orientation(2); private int value; private Orientation(int v) { value = v; } }
写出一个 Orientation 类型的值, 并再次将其读回:
Orientation original = Orientation.HORIZONTAL; ObjectOutputStream out = . . . ; out.write(original); out.close(); ObjectInputStream in = . . . ; Orientation saved = (Orientation) in.read();
测试:
if (saved == Orientation.HORIZONTAL) . . .
读回对象并非枚举对象,即创建了一个新对象(即使构造器私有)。
解决:类中定义了“readResolve”方法
- (对象被序列化之后就会调用它)
- “readResolve”方法将检查“value”域并返回恰当的枚举常量:
protected Object readResolve() throws ObjectStreamException { if (value == 1) return Orientation.HORIZONTAL; if (value == 2) return Orientation.VERTICAL; throw new ObjectStreamExcepti on(); // this shou1dn't happen }
版本管理(serialVersionUID)
如果一个类具有名为“serialVersionUID”的静态数据成员,它就不再需要人工地计算其指纹,而只需直接使用这个值:
- (对象输入流将拒绝读入具有不同指纹的对象)
class Employee implements Serializable // version 1.1 { . . . public static final long serialVersionUID = -1814239825517340645L; }
- 类的方法产生了变化:那么在读人新对象数据时是不会有任何问题的。
- 类的数据域产生了变化:(只会考虑非瞬时和非静态的数据域)
- 如果两部分数据域之间“名字匹配而类型不匹配”,因为这两个对象不兼容(对象输入流不会尝试将一种类型转换成另一种类型);
- 如果“被序列化的对象具有在当前版本中所没有的数据域”,那么对象输入流会忽略这些额外的数据;
- 如果“当前版本具有在被序列化的对象中所没有的数据域”,那么这些新添加的域将被设置成它们的默认值(如果是对象则是“null”,如果是数字则为“0”,如果是boolean值则是“false”)。
获取类的指纹(JDK 中的单机程序“serialver”):
- 命令:
serialver Employee- 结果:
Employee: static final long serialVersionUID = -1814239825517340645L;
- 结果:
- 图形化:
serialver -show Employee
为克隆使用序列化
操作文件
Path 读写文件 创建文件和目录 复制、移动和删除文件 获取文件信息 访问目录中的项 使用目录流 ZIP 文件系统
内存映射文件
内存映射文件的性能 缓冲区数据结构 文件加锁机制 正则表达式