核心技术Ⅱ:I/O
跳到导航
跳到搜索
输入/输出流
- 在 Java API 中:
- 输入流:可以从其中读入一个字节序列的对象;
- 输出流:可以向其中写入一个字节序列的对象;
- 使用方法的不同:
- 字节流:抽象类“InputStream”和“OutputStream”构成了I/O类层次结构的基础;
- (不便于处于Unicode形式存储的信息)
- 字符流:抽象类“Reader”和“Writer”构成的专门用于处理“Unicode”字符的单独的类层次结构;
- (读写操作基于两字节的Char值,即Unicode码元,而非基于byte值)
- 字节流:抽象类“InputStream”和“OutputStream”构成了I/O类层次结构的基础;
- 输入/输出,都是相对于内存理解。
- 何时使用字节流、何时使用字符流?
- 字节流操作的基本单元为字节;字符流操作的基本单元为Unicode码元。
- 字节流默认不使用缓冲区;字符流使用缓冲区。
- 字节流通常用于处理二进制数据(实际上它可以处理任意类型的数据,但不支持直接写入或读取Unicode码元);字符流通常处理文本数据,支持写入及读取字符(Unicode码元)。
读写字节
- “abstract int read()”方法:(“InputStream”类的抽象方法)读入一个字节,并返回读入的字节,或者在遇到输入源结尾时返回“-1”;
- (继承于InputStream的具体输入流类,必须覆盖这个方法以提供适用的功能)
- (InputStream 类还有若干个非抽象的方法,可以读入一个字节数组,或者跳过大量的字节。这些方法都要调用抽象的“read”方法,因此,各个子类都只需覆盖这一个方法)
- “int read(byte[] b)”:用于读入一个字节数组;
- “abstract void write()”方法:(“OutputStream”类的抽象方法)向某个输出位置写出一个字节;
- (“write”与“read”类似,被其他方法调用,具体输出类需要实现该方法)
- “void write(byte[] b)”:用于写出一个字节数组;
- “write”与“read”方法,在执行时都将阻塞,直到字节处理完毕;
- “available”方法:检查当前可读入的字节数量:
- 则,以下代码片段不能被阻塞:
int bytesAvailable = in.available(); if (bytesAvai1able > 0) { byte[] data = new byte[bytesAvai1able]; in.read(data); }
- “flush”方法:刷新输出流的缓冲区;
- “close”方法:关闭输入/输出流,释放系统资源;
- (关闭一个输出流的同时还会冲刷用于该输出流的缓冲区)
- 如果不关闭文件,那么写出字节的最后一个包可能将永远也得不到传递。
- 【一般使用众多的从基本的“InputStream”和“OutputStream”类导出的某个输入/输出类,而不只是直接使用字节。】
- (数据可能包含数字、字符串和对象,而不是原生字节)
相关方法
java.io.InputStream1.0
- abstract int read()
- 从数据中读人一个字节,并返回该字节。这个 read 方法在碰到输入流的结尾时返回 -1
- int read(byte[] b)
- 读入一个字节数组,并返同实际读入的字节数,或者在碰到输人流的结尾时返同 -1,这个 read 方法最多读入 b.1ength 个字节。
- int read(byte[] b, int off, int len)
- 读入个字节数组。这个 read 方法返回实际读入的字节数, 或者在碰到输入流的结尾时返回-1
- 参数 : b 数据读入的数组
- off 第一个读入字节应该被放置的位置在 b 中的偏移量
- len 读入字节的最大数量
- long skip(long n)
- 在输入流中跳过n个字节,返回实际跳过的字节数(如果碰到输入流的结尾,则可能小于n)。
- int available()
- 返回在不阻塞的情况卜可获取的字节数(回忆一下,阻塞意味着当前线程将失去它对资源的占用)。
- void close()
- 关闭这个输入流。
- void mark(int readlimit)
- 在输入流的当前位置打一个标记(并非所有的流都支待这个特性。如果从输入流中已经读入的字节多于readlimit个,则这个流允许忽略这个标记。
- void reset()
- 返回到最后一个标记,随后对 read 的调用将重新读入这些字节。如果当前没有任何标记,则这个流不被重置。
- boolean markSupported()
- 如果这个流支持打标记,则返回true。
java.io.OutputStream 1.0
- abstract void write(int n)
- 写出一个字节的数据。
- void write(byte[] b)
- void write(byte[J b, int off, int len)
- 写出所有字节或者某个范围的字节到数组b中 。
- 参数 : b 数据读入的数组
- off 第一个读入字节应该被放置的位置在 b 中的偏移量
- len 读入字节的最大数量
- void close()
- 冲刷并关闭输出流。
- void flush()
- 冲刷输出流,也就是将所有缓冲的数据发送到目的地。
流家族
- 输入流与输出流的层次结构:
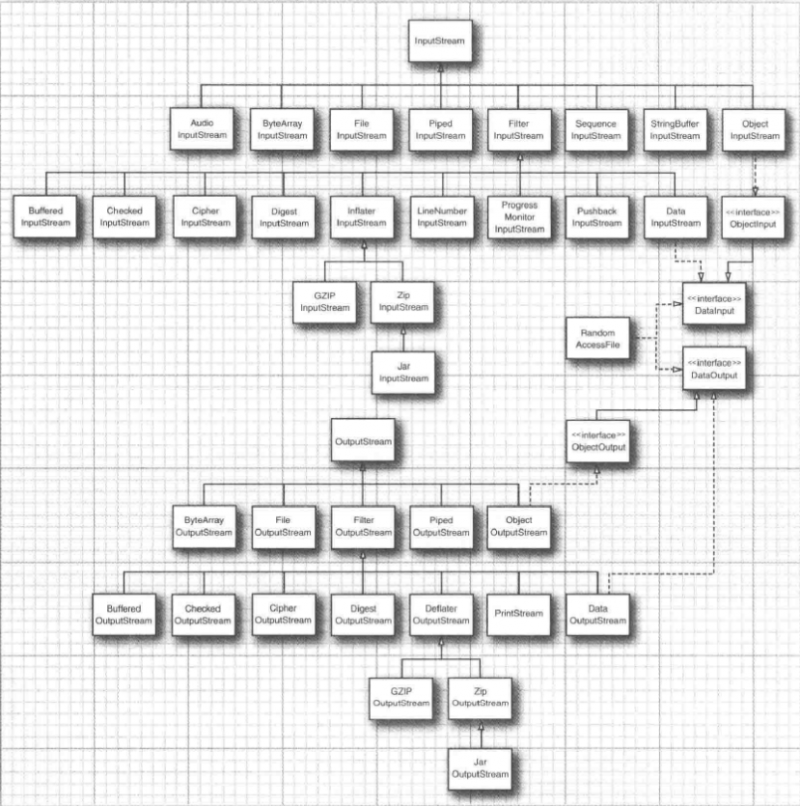
- 要想读写字符串和数字,就需要功能更强大的子类,如:
- “DataInputStream”和“DataOutputStream”可以以二进制格式读写所有的基本Java类型;
- “ZipInputStream”和“ZipOutputStream”可以以常见的ZIP压缩格式读写文件;
- Reader和Writer的层次结构:
- 附加接口:
- “Closeable”:
void close() throws IOException- (“InputStream”、“OutputStream”、“Reader”和“Writer”都实现了“Closeable”接口)
- (“java.io.Closeable”接口扩展了“java.lang.AutoCloseable”接口,因此,对任何“Closeable”进行操作时,都可以使用“try-with-resource”语句)
- (“java.io.Closeable”抛出“IOException”;“java.lang.AutoCloseable”可以抛出任意异常)
- “Flushable”:
void flush()- (“OutputStream”和“Writer”还实现了“Flushable”接口)
- “Readable”:
int read(CharBuffer cb)
- “Appendable”:
// 添加单个字符 Appendable append(char c) // 添加字符序列 Appendable append(CharSequence s)- 只有“Writer”实现了“Appendable”;



【CharBuffer、CharSequence、String、StringBuilder、StringBuffer】
CharBuffer、CharSequence、String、StringBuilder、StringBuffer
组合输入/输出流过滤器
Java 使用了一种灵巧的机制来分离这两种职责:
- 某些输入流(如“FileInputStream”和由 URL 类的“openStream”方法返回的输入流)可以从文件和其他更外部的位置上获取字节,
- 而其他的输入流(如“DatainputStream”) 可以将字节组装到更有用的数据类型中。
Java 程序员必须对二者进行组合,通过嵌套过滤器来添加多重功能。
例如:
- 为了从文件中读入数字,首先需要创建一个FileinputStream,然后将其传递给“DataInputStream”的构造器:
FileinputStream fin = new FileinputStream("employee.dat"); DataInputStream din = new DataInputStream(fin); doub1ex = din.readDouble();
- 使用缓冲机制,以及用于文件的数据输入方法:
DataInputStream din = new DataInputStream( new BufferedinputStream( new Fi1eInputStream("emp1oyee.dat")));
- 跟踪各个中介输入流(当读人输入时,预览下一个字节,以了解它是否是你想要的值):
- (读入和推回是可应用于可回推(pushback)输入流的仅有的方法)
PushbackInputStream pbin = new PushbackInputStream( new BufferedlnputStream( new FilelnputStream("employee.dat"))); // 预读下一个字节: int b = pbin.read(); // 并非期望值时将其推回流中 if(b != '<') pbin.unread(b);
- 预先浏览并且还可以读入数字(需要一个既是可回推输入流,又是一个数据输入流的引用):
DataInputStream din = new DataInputStream( pbin = new PushbackInputStream( new BufferedInputStream( new Fi1eInputStream("emp1oyee.dat"))));
- 从一个ZIP 压缩文件中通过使用下面的输入流序列来读入数字:
ZipInputStream zin = new ZipInputStream(new Fi1eInputStream("emp1oyee.zip")); DataInputStream din = new DataInputStream(zin);
文本输入/输出(文本即字符)
在存储文本字符串时,需要考虑字符编码(character encoding)方式。
- 在 Java 内部使用的“UTF-16”编码方式中,字符串“1234”编码为“00 31 00 32 00 33 00 34”(十六进制)。但是,以“UTF-8”编码方式中为“4A 6F 73 C3 A9”;
文本:输入(“PrintWriter”)/输出(“Scanner”)
写出文本
“PrintWriter”:文本格式打印字符串和数字;
- 它有一个将“PrintWriter”链接到“FileWriter”的便捷方法:
PrintWriter out = new PrintWriter("employee.txt", "UTF-8"); // 等同于 PrintWriter out = new PrintWriter(new Fi1eOutputStream("employee.txt"), "UTF-8");
- 需要使用与“System.out”类似的“print、println”和“printf”方法;
- (可以用这些方法来打印数字:int、short、1ong、float、double,字符,boolean值,字符串,及对象)
- 如果写出器为自动冲刷模式,则每次调用“println”时,缓冲区中的字符都会被发送到目的地(打印写出器总是带缓冲区的);
- (自动冲刷机制,默认禁用)
PrintWriter out = new PrintWriter( new OutputStreamWriter( new Fi1eOutputStream("employee.txt"), "UTF-8"), true); // auto flash
- “print”方法不抛出异常,可以调用“checkError”方法来杳看输出流是否出现了某些错误;
- 关于行结束符:
- Windows 系统是“\r\n”;UIX 系统是“\n”;
- 可以通过“System.getProperty("line.separator")”获得目标系统行结束符;
- “println”方法在行中添加了对目标系统来说恰当的行结束符;
读入文本
读入文本方式:
- 最简单的任意文本处理:“Scanner”类;【见[1]】
// 通过输入流构造“Scanner”对象 Scanner in = new Scanner(System.in); // 读取输入行 String name = in.nextLine(); // 读取字符串(以空格符作为分隔) String firstName = in.next(); // 读取整数 int age = in.nextInt(); //读取浮点数 double salary = in.nextDouble();
- 短文本:(直接读取到一个字符串)
String content = new String(Files.readAllBytes(path), charset);
- 文本按行读入:(读取到一个字符串集合)
List<String> 1ines = Files.readAllLines(path,charset);
- 长文本:(利用流“Stream<String>”)
try (Stream<String> lines = Files.lines(path, charset)) { . . . }
- (Java早期版本)通过“BufferReader”类:
InputStream inputStream = . . . ; try (BufferedReader in = new BufferedReader(new InputStreamReader(inputStream, StandardCharsets.UTF_8))) { String line; while ((line = in.readline()) != null) { // do something with line } }
- “BufferedReader”类有一个“lines”方法,可以产生一个“Stream<String>”对象。
- “BufferedReader”与“Scanner”不同,没有任何用于读入数字的方法。
【转换流】
转换流:(在“字节流”与“字符流中转换”)
- “OutputStreamWriter”:将使用选定的字符编码方式,把 Unicode 码元的输出流转换为字节流。
- 继承于“Writer”,是字符流通向字节流的桥梁;【写出:字符 -> 字节】
- “InputStreamReader”:将包含字节(用某种字符编码方式表示的字符)的输入流转换为可以产生 Unicode 码元的读入器。
- 继承于“Reader”,是字节流通向字符流的桥梁;【读入:字节 -> 字符】
Reader in = new InputStreamReader(System.in); Reader in = new InputStreamReader(new Fi1eInputStream("data.txt"), StandardCharsets.UTF_8);
- 【“字节流”用于输出输出;“字符流”:用于代码中操作】
- 应用如“基于Socket的聊天系统”:“字节流”用于传输;“字符流”在客户端显示;
- “OutputStreamWriter”与“InputStreamReader”属于字符流“Reader/Writer”结构层次;
【缓冲字符高级流:“BufferedWriter”和“BufferedReader”】
- 以“行”作为单位,进行读取/写出;
- “BufferedReader”是“缓冲字符输入流”;
- “BufferedWriter”是“缓冲字符输出流”;
【“OutputStreamWriter”、“PrintWriter”与“BufferedWriter”】
| OutputStreamWriter | PrintWriter | BufferedWriter |
|---|---|---|
|
|
|
- 需要字节流转换为字符流时使用“OutputStreamWriter”;需要文本输出使用“PrintWriter”;
字符编码方式
Java 针对字符使用的是 Unicode标准,有多种不同的字符编码方式:
- “UTF-8”:(最常用)
- 将每个Unicode编码点编码为1到4个字节的序列。(好处是ASCII字符集中的每个字符都只会占用一个字节)
- “UTF-16”:(Java字符串中使用的编码方式)
- 将每个Unicode编码点编码为1个或2个16位值。(分为“高位优先”和“低位优先”两种形式,通过文件的“字节顺序标记”来确定)
- UTF-8编码的文件不需要字节顺序标记;
“StandardCharsets”类具有类型为“Charset”的静态变量,用于表示每种Java虚拟机都必须支持的字符编码方式:
- StandardCharsets.UTF_8
- StandardCharsets.UTF_16
- StandardCharsets.UTF_16BE
- StandardCharsets.UTF_16LE
- StandardCharsets.IS0_8859_1
- StandardCharsets.US_ASCII
- 为了获得另一种编码方式的“Charset”, 可以使用静态的“forName”方法:
Charset shiftJIS = Charset.forName("Shift-JIS");
- 在读入或写出文本时,应该使用“Charset”对象:
// 将一个字节数组转换为字符串 String str = new String(bytes, StandardCharsets.UTF_8);
- “Charset.defaultCharset”:静态方法,返回平台使用的编码方式;
- “Charset.availableCharsets”:静态方法,返回所有可用的“Charset”实例;
- 在不指定任何编码方式时,有些方法会使用默认的平台编码方式(如“String(byte[])”构造器),而其他方法会使用UTF-8(例如“Files.readAlllines”) 。
- Oracle的Java实现有一个用于覆盖平台默认值的系统属性“file.encoding”,但并非官方支持的属性,不应使用。
读写二进制数据
DataInput 和 DataOutput 接口 随机访问文件 ZIP 文档
对象输入/输出流与序列化
保存和加载序列化对象 理解对象序列化的文件格式 修改默认的序列化机制 序列化单例和类型安全的枚举 版本管理 为克隆使用序列化
操作文件
Path 读写文件 创建文件和目录 复制、移动和删除文件 获取文件信息 访问目录中的项 使用目录流 ZIP 文件系统
内存映射文件
内存映射文件的性能 缓冲区数据结构 文件加锁机制 正则表达式